
![]()
The Research Lifecycle: A Primer on Open and Sustainable Science Practices
- This OHBM 2026 Educational Course is organized as a joint effort between the OHBM Open Science and Sustainability and Environmental Action Special Interest Groups (OS-SIG/SEA-SIG).
- Open and sustainable research practices go together throughout the entirety of the scientific process from data management and sharing, to preprocessing and analysis, and beyond.
- This educational course will address the topic of open and sustainable science throughout each step of the process, with each talk speaking to a different part of the research “lifecycle.”
- This format makes open and sustainable science practices approachable for trainees and early career researchers, as well as established investigators looking to refine their scientific processes.
Organizers:
Chloe E Page, Martin Nørgaard, Muriah D Wheelock, Eva van Heese
Schedule
| Start Time | Title | Speaker(s) |
|---|---|---|
| 13:30 | Welcome and introduction | Chloe E Page, Nicholas Souter |
| 13:40 | Research data management for transparent and sustainable science | Felix Hoffstaedter |
| 14:10 | Poppy and Bagel: Promoting open and sustainable science by simplifying sharing of processed datasets | Nikhil Bhagwat |
| 14:40 | Compute Once, Reuse Forever - Sustainable Science with NiPreps | Christopher J Markiewicz |
| 15:10 | Q&A panel | — |
| 15:15 | Break | — |
| 15:25 | Software containers demystified: build your own or use what’s already there | Fernanda L Ribeiro, Franco Pestilli |
| 15:55 | Efficient large-scale statistical analyses in the big data era | Pravesh Parekh |
| 16:25 | Measuring and reducing the carbon footprint of neuroimaging studies | Nicholas Souter |
| 16:55 | Q&A panel | — |
| 17:00 | End | — |
Presentations
Research data management for transparent and sustainable science: Felix Hoffstaedter
About the speaker: Felix is a research scholar at the Research Centre Jülich building reproducible data processing pipelines that are usable on the average laptop as well as in high performance computing environments. He is a strong advocate of Datalad as a basic tool for FAIR data management, processing and sharing. His current focus is to develop easy-to-use workflows for fully reproducible data processing and to analyze the impact of data quality on common statistical approaches and machine learning models. As part of the OS-SIG, Felix served as Open Science Room Chair in 2018 and currently serves as Hackathon co-chair elect.
About the talk: The joint management of code and data holds immense value not only for the respective research project itself but for each lab’s internal or external follow-up studies, even given the common case that large parts of the data used cannot be publicly shared. Shared data derivatives also represent a key aspect of sustainable science in the sense of transparent research practices as well as adhering to the ecological necessity of not wasting energy for recomputing the same outcome. Using a prototypical study setup, the talk will go through 3 versions of joint code and data provenance tracking to produce an increasing amount of meta-data using Datalad: 1. minimal snapshot approach, 2. step-wise state capture, 3. comprehensive, re-executable workflow documentation.
Poppy and Bagel: Promoting open and sustainable science by simplifying sharing of processed datasets: Nikhil Bhagwat
About the speaker: Nikhil is an early career researcher at the Neuro, McGill University and a maintainer of the Nipoppy and Neurobagel projects. He is involved in multiple open science and sustainable neuroimaging initiatives and has organized several open-science workshops and educational courses. He is a past treasurer for the SEA-SIG within OHBM and active in global consortia projects including ENIGMA-PD where he trains and supports adoption of open-science tools and practices to promote reproducible and inclusive research.
About the talk: Open, large-scale, inclusive datasets - everyone wants them! Yet, today’s research studies are shaped by increasingly stringent data governance, resulting in siloed data sources with heterogeneous sharing policies. In this module, we will discuss the challenges associated with sharing and pooling data from decentralized data sources and tools that can help address them in an efficient and sustainable manner. Specifically, we will talk about 1) Nipoppy: a lightweight neuroinformatics framework to standardize data workflows to ensure reusability and comparability of multi-centre datasets in downstream analyses, 2) Neurobagel: an ecosystem of tools that enables discovery of multimodal, multi-centre datasets to establish availability of processed data at the sample level. We will show how these tools can help researchers standardize data organization and processing critical for making multi-site data interoperable. This module will promote sharing of well curated, processed datasets under varying degrees of data governance which can have massive impact both in terms of FAIR datasets and reduction of carbon footprint from compute-heavy neuroimaging pipelines.
Compute Once, Reuse Forever - Sustainable Science with NiPreps: Christopher J Markiewicz
About the speaker: Chris is a research scholar at Stanford University in the United States. His work focuses on open tools and standards for processing and publishing neuroimaging data.
About the talk: Ever struggled to combine neuroimaging datasets from different scanners? This talk tackles that challenge head-on. We’ll introduce the NiPreps ecosystem and its powerful “Fit+Transform” model—a strategy for separating heavy computation from flexible, lightweight analysis. You’ll learn how this approach makes your science more reproducible, FAIR, and environmentally sustainable. Best of all, we’ll put theory into practice with a live, hands-on demo, showing you exactly how to reuse pre-computed results: demo link
Software containers demystified: build your own or use what’s already there: Fernanda L Ribeiro
About the speaker: Fernanda is a visual neuroscientist and a Marie Curie fellow at the University of Giessen in Germany. She has been contributing to the open science community by developing scientific software and contributing to Neurodesk. She will discuss software containers more broadly, as well as Neurodesk. Franco Pestilli, Professor of Psychology at the University of Texas at Austin and Director of BrainLife, will join her on stage to discuss BrainLife.
About the talk: Software containers are revolutionizing neuroimaging research, but terms like Dockerfile, Docker image, and Singularity container can feel intimidating. This talk cuts through the jargon. We’ll introduce core concepts, explore a popular containerization platform, and show how containers enable reproducible workflows through user-friendly platforms like Neurodesk and BrainLife. No container-building required—you’ll learn how to leverage existing solutions to streamline your research, scale analyses, and collaborate more effectively, all while avoiding the usual software configuration headaches.
Efficient large-scale statistical analyses in the big data era: Pravesh Parekh
About the speaker: Pravesh is a bioinformatics engineer at the J. Craig Venter Institute (United States) and a researcher at the University of Oslo (Norway). He develops and applies novel statistical methods to analyze multimodal neuroimaging and genetic data in large-scale studies like the ABCD Study and the UK Biobank.
About the talk: Performing statistical analyses for studies like the UK Biobank and the ABCD Study is computationally intensive, having long running time, racking up steep cloud computing bills, and leaving a substantial carbon footprint. In this tips-and-tricks style talk, I will present practical solutions for working with these studies, managing massive amounts of input and output data, and statistical challenges including whole-brain scalability. I will show how making tweaks to everyday code can make our analytical pipelines faster, cheaper, and greener. I will also introduce tools like FEMA, BLMM, and modelArray designed for performing large-scale statistical analyses. The code used for the demos (spanning R, Python, and MATLAB) is available here: demo link
Measuring and reducing the carbon footprint of neuroimaging studies: Nicholas Souter
About the speaker: Nick is post-doc fellow at University of Sussex. His work focuses on ways of measuring and reducing the carbon footprint of functional magnetic resonance imaging (fMRI) data analysis. This work is motivated by a recent push for scientists to reflect on how their research activities contribute to the climate crisis, and understand how this impact can be reduced. Nick has been leading the green-computing working group of the SEA-SIG within OHBM and is now their chair-elect.
About the talk: All aspects of the neuroimaging research process, spanning data collection, data processing, and data storage use energy, and therefore have a carbon footprint. In this talk I’ll discuss the environmental impact of each of these processes, and provide evidence-based recommendations for researchers to make their data processing and analysis more efficient.
MATERIALS
Examples will be run on a public Neurodesk Play cloud instance at https://play-europe.neurodesk.org/. This instance is enabled through services and resources provided by the EGI Federation, with dedicated support from CESNET-MCC. Computational resources were provided by the e-INFRA CZ project (ID:90254), supported by the Ministry of Education, Youth and Sports of the Czech Republic. Course materials will remain available on the Neurodesk Play instance for 2 months after the conference.
Neurodesk’s documentation at neurodesk.org includes a short getting-started guide for new users. Neurodesk Play is a browser-based Neurodesk instance that gives you access to a full suite of neuroimaging tools, with no local installation required.

For any questions, you can reach us at ohbmopenscience@gmail.com or find us in the Open Science Room at OHBM 2026 (Room H).
![]()
Maximizing scientific efficiency through sustainability, reproducibility, and FAIRness
-
This OHBM 2025 Educational Course is organized as a joint effort between the OHBM Open Science and Sustainability and Environmental Action Special Interest Groups (OS-SIG/SEA-SIG).
-
Adopting sustainable, FAIR-aligned (Findable, Accessible, Interoperable, Reusable) approaches to data sharing and processing is still limited across the field and the environmental impact of high computational demands in neuroimaging research is a growing concern.
-
Presenters will introduce principles and best practices in FAIR data sharing, sustainable computing, and open science, alongside practical tutorials on tools and techniques for creating transparent, reproducible workflows.
-
By addressing these topics as an educational course, this program aims to lower current barriers for FAIR principles, foster a culture of reproducibility and sustainability, and promote resource efficiency in the neuroimaging community.
Organizers:
Muriah Wheelock, Nikhil Bhagwat, Niousha Dehestani, Naomi Gaggi
Schedule
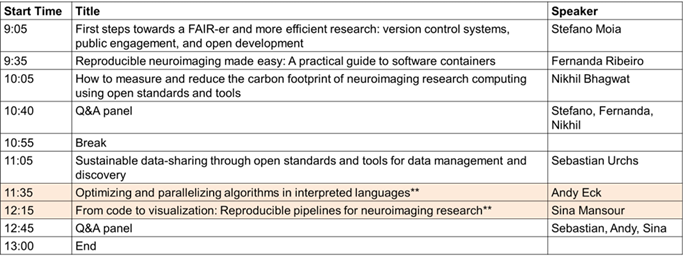
** Interactive Notebooks